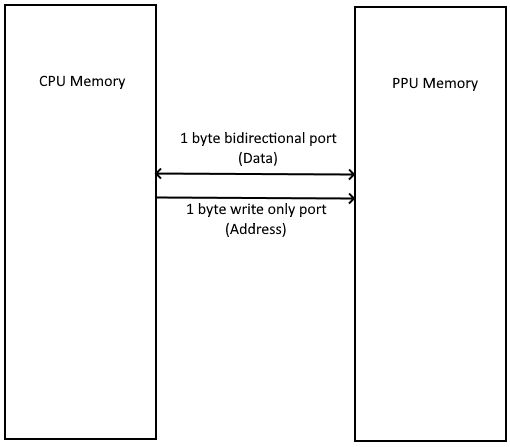
Click on picture for more details about the ports (From NESDEV wiki)
| Home |
NES |
Atari 2600 |
Neo geo Pocket Color |
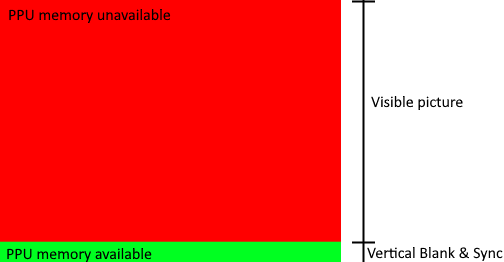
Click on picture for more details about the ports (From NESDEV wiki) |
|
| Length Value |
Meaning |
| 00 |
End of strings |
| 01 |
Plot Mode |
| 02 - 3F |
Literal to right: Copy n+1 bytes to video
memory addresses increasing to right |
| 40 - 7F |
Run to right: Copy one byte n-63 times to
video memory address increasing to right |
| 80 - BF |
Literal down: Copy n - 127 bytes to video
memory addresses increasing down |
| C0 - FF |
Run down: copy one byte n - 191 times to
video memory addressing increasing down |
| 6502 Rolled Loop ldx #8 ;2 - jsr SomeFunction ;12 dex ;2 bne - ;3 / 2 Bytes: 8 Cycles: 137 |
6502 unrolled loop jsr SomeFunction ;12 jsr SomeFunction ;12 jsr SomeFunction ;12 jsr SomeFunction ;12 jsr SomeFunction ;12 jsr SomeFunction ;12 jsr SomeFunction ;12 jsr SomeFunction ;12 Bytes: 36 Cycles: 96 |